HashMap 简介
HashMap 主要用来存放键值对,它基于哈希表的Map接口实现,是常用的Java集合之一。
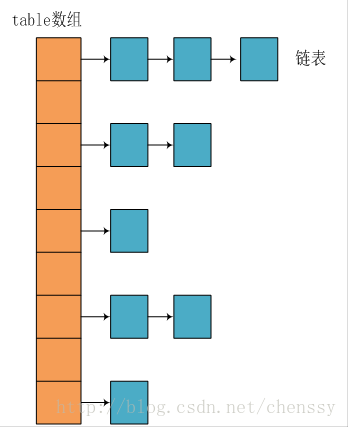
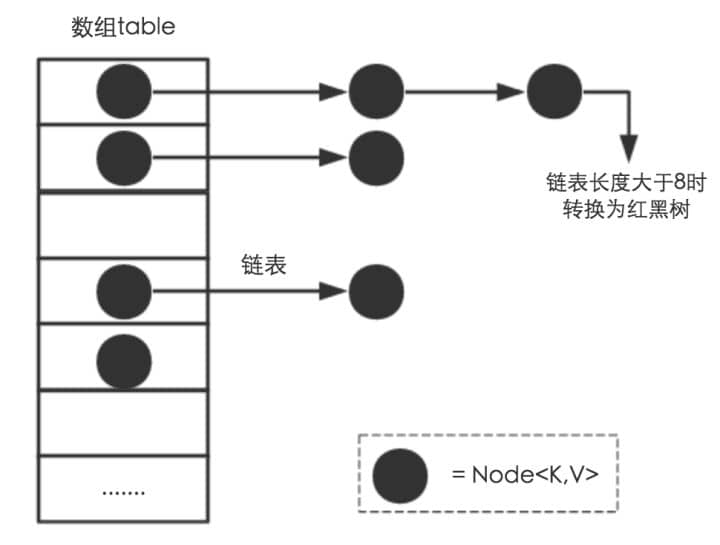
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
底层数据结构分析
JDK1.8之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
1 | static final int hash(Object key) { |
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
1 | static int hash(int h) { |
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
类的属性:
1 | public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { |
loadFactor加载因子
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
threshold
threshold = capacity * loadFactor,当Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。
Node节点类源码:
1 | // 继承自 Map.Entry<K,V> |
树节点类源码:
1 | static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { |
HashMap源码分析
构造方法

1 | // 默认构造函数。 |
putMapEntries方法:
1 | final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) { |
put方法
HashMap只提供了put用于添加元素,putVal方法只是给put方法调用的一个方法,并没有提供给用户使用。
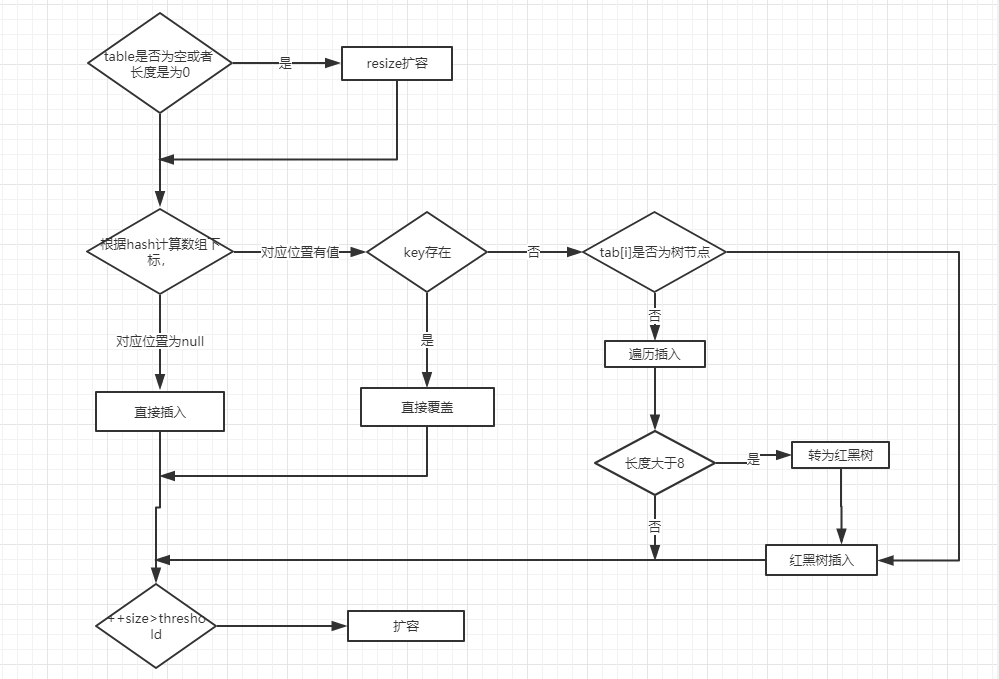
对putVal方法添加元素的分析如下:
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
1 | public V put(K key, V value) { |
我们再来对比一下 JDK1.7 put方法的代码
对于put方法的分析如下:
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的key比较,如果key相同就直接覆盖,不同就采用头插法插入元素。
1 | public V put(K key, V value) |
get方法
1 | public V get(Object key) { |
resize方法
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
1 | final Node<K,V>[] resize() { |
HashMap常用方法测试
1 | package map; |